
Introduction
In one of my previous projects, I worked as a backend engineer managing multiple PHP and Java microservices. We used MySQL as the primary database and relied on Change Data Capture (CDC) with Zendesk Maxwell to synchronize data between services.
CDC was responsible for delivering quotes, prices, and sales data from our main microservice to a quotes microservice. Unfortunately, for over two years, the team struggled with data mismatches and delayed synchronization, causing incorrect prices on our product listings.
This blog explains how I diagnosed and fixed the issue by writing a custom SQS batched producer, dramatically improving performance and stability.
The Problem: Mismatched Data and Slow Synchronization
Our CDC pipeline used AWS SQS FIFO queues as the transport layer. The FIFO design helped maintain message order, but with high website traffic, we often exceeded processing capacity.
Key issues:
- Messages in SQS consistently stayed above 10,000 in the queue.
- The consumer service could not keep up with the producer speed.
- CPU and memory usage were constantly maxed out.
- The only fix was to restart the quotes service to rebuild the index — essentially making CDC useless.
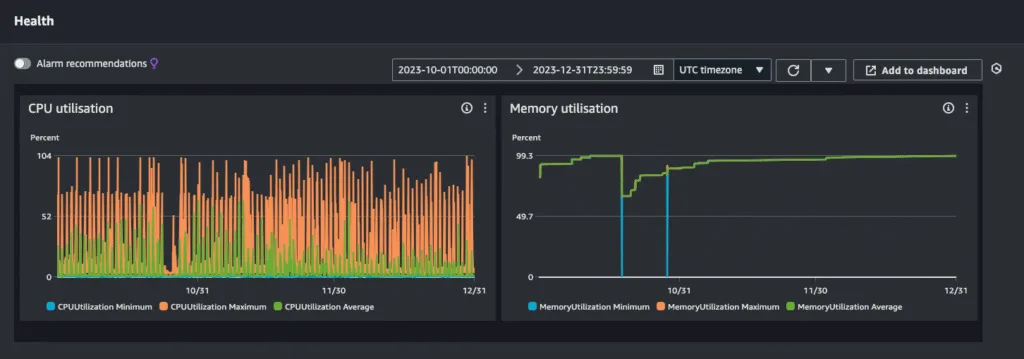
Finding the Bottleneck
In late December, I decided to dig deep into the issue. After several hours of log analysis, I found that:
- CPU and memory usage were extremely high for the last three months.
- The SQS FIFO queue was hitting its throughput limit of 300 messages per second.
- Maxwell’s built-in SQS producer pushed one message per event, resulting in excessive load during high-traffic periods.
The Breakthrough: Batch Message Sending
AWS SQS FIFO queues support batching — sending up to 10 messages in a single batch, effectively multiplying throughput to 3,000 messages per second.
However, Maxwell’s built-in SQS producer did not support FIFO batching. Luckily, Maxwell allowed custom producer implementations.
Building the Custom Batched Producer
I developed a custom SQS batched producer to wrap multiple CDC events into a single SQS batch request. This change drastically reduced the number of API calls to SQS and allowed us to fully utilize its batch capabilities.
The result:
- CPU and memory usage dropped significantly.
- Message backlog cleared quickly, even during traffic spikes.
- Data mismatches between services were resolved.
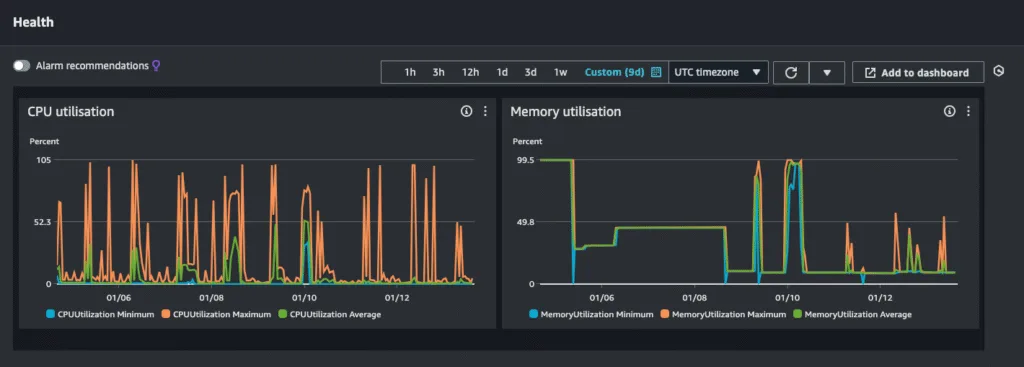
Results and Impact
The difference was night and day:
- Before: Constantly high CPU & memory usage, delayed updates, mismatched prices.
- After: Stable system, quick synchronization, accurate prices.
This fix not only improved performance but also restored the reliability of our CDC pipeline, removing a pain point the team had struggled with for over two years.
Conclusion
Sometimes, performance problems are not caused by complex bugs, but by architectural limitations. By leveraging SQS batching and customizing the CDC producer, I was able to significantly improve throughput and reliability in our microservices system.
It was a satisfying moment to finally say: “It works!” — knowing the entire team could now trust our data synchronization process again.